
Субъективное восприятие знания в голове можно разделить на несколько групп: мало что знаю и признаю́ это; что-то знаю и смогу объяснить простые вещи; много знаю и растолкую почти всё. Опасней всего оказаться во второй категории, когда кажется, что накопленной информации достаточно, чтобы комментировать новости и давать советы. Тема этой статьи — как раз из такого ряда знаний: вроде очевидно, а копнешь — всё сложно.
Есть в микроэлектронике такое понятие, как технорма (technology node; иногда пишут «critical dimension» — критический размер, но сейчас это разные понятия), ныне измеряемая теми самыми любимыми маркетологами нанометрами. Задача дать определение этому важнейшему термину не столь проста, как кажется. Когда-то под технормой понимался самый малый по длине или ширине элемент, формируемый данным технологическим процессом на фабрике (фабе, как говорят сами чиподелы). То есть для массового изготовления микросхем производственное и измерительное (метрологическое) оборудование настраивается на такой набор установок, который позволяет формировать на кристалле структуры с желаемыми параметрами и размерами — причем первое сильно зависит от второго.
Помимо технормы также важны: число слоев межсоединений (тонкие металлические и поликремниевые дорожки-проводки, соединяющие выводы транзисторов), диаметр кремниевой пластины (на ней формируется рисунок для сотен или тысяч будущих кристаллов, которые после ее распила вставят в отдельные корпуса), различные оптимизации под скорость и/или энергоэффективность и пр. С точки зрения верящего в прогресс оптимиста, главное во всем этом то, что на передовых фабах переход на новый техпроцесс происходит примерно каждые два года и является причиной выполнения «закона Мура» (хотя по факту это никакой не закон, а эмпирическая закономерность, самосбывающаяся лишь потому, что производители все еще готовы вкладывать в это деньги). Правда, рядом тут же появляется пессимист и язвительно замечает, что у слов «новый техпроцесс» может оказаться крайне неприятное для оптимиста толкование…
Самые главные (и дорогие) станки для производства микросхем — фотолитографы: именно они формируют рисунок из засветов на светочувствительном слое фоторезиста, который при травлении «чертит» очередной слой чипа. Когда технорма стала меньше длины волны света, используемого в их лазерах (а это произошло в конце 1990-х годов — вскоре после внедрения техпроцесса 250 нм), появилось два отдельных определения: для так называемых регулярных чипов (память, программируемые матрицы, фотодатчики — в том числе со встроенными логическими блоками) и для нерегулярных (сложная логика, часто содержащая кэши, буферы и все похожее на них). Тут речь идет о повторяющихся структурах на кристалле: например, ячеек любого вида памяти на современной большой микросхеме — миллиарды, но разных их видов — всего несколько. Так вот: для регулярных чипов того времени технорма — минимальный полушаг линейно-регулярной структуры (то есть одномерного ряда чего-то), а для нерегулярных — минимальная ширина дорожки нижнего уровня металла с контактами (что примерно вдвое длиннее затвора транзистора).
Однако с конца 2000-х годов (точнее — с внедрения процессов 45 нм) и эти определения перестали иметь значение. Дело в том, что число фабрик, производящих микросхемы по самым современным техпроцессам, неуклонно снижается (о чем далее). При этом ни одна фирма, выпускающая оборудование для производства полупроводников, сами полупроводниковые микросхемы не делает, и все производители микросхем покупают станки у примерно одних и тех же (и тоже весьма малочисленных) фирм. Скажем, если исчезнут ASML и Applied Materials, то все чиподелы мира встанут колом. Очевидно, собираемые из установок и настроек техпроцессы на фабах получились бы как две капли воды похожи, но смысл это имеет лишь для нескольких фабов одной компании, а компаний с несколькими фабами в мире — единицы. Так что каждая фирма пытается удовлетворить заказчиков чем-то особенным, выпускаемым на почти стандартном оборудовании. И вот тут под нож и пошли те самые нанометры…
До субмикронных технорм (когда их и измеряли микронами, а не нанометрами) действовало простое лямбда-правило (этой греческой буквой обозначается длина волны света): если не считать разные оптические тонкости, влияющие на так называемую числовую апертуру, то при уменьшении длины волны вдвое можно формировать вдвое меньшего размера и сами структуры, главная из которых — длина затвора транзистора. Это дает вдвое бо́льшие достижимые частоты, вдвое меньшее напряжение питания и ввосьмеро (!) меньшее потребление на одно переключение транзистора между открытым и закрытым состояниями. Ясно, что такие идеалы вообще ни в какой микросхеме ни разу не соблюдались, но лучшие образцы вполне приближались к ним. (Тут автор позволит себе освободить читателя от созерцания лишних формул и таблиц.)
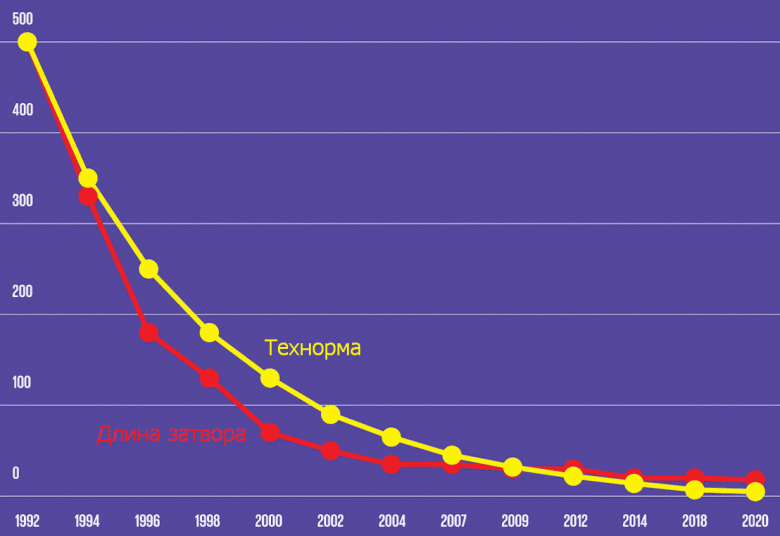
В 1990-е годы, после перехода на технормы менее микрона, стало применяться альфа-правило: теперь размеры отдельных элементов домножались на определенный коэффициент, который для очередного техпроцесса оказывался не обязательно линейно соответствующим разнице в технорме. Если точнее, каждый следующий шаг процесса выбирается примерно на 30% меньше предыдущего — вот откуда получается всем известный «нанометровый» ряд: 350, 250, 180, 130, 90, 65, 45, 32, 22… Можно наивно предположить, что основные параметры транзистора (частота, потребление и размеры) должны ровно так же уменьшаться на тот же коэффициент (в нужной степени). В реальности же длина затвора сначала падала быстрее уменьшения размера технормы, а затем медленнее. Прочие величины также уменьшаются слабее, а в 2010-х годах у отдельных фирм стали появляться чудеса и покруче, когда размеры отдельных частей вообще не меняются в новом процессе.
| Момент демонстрации | Компания (-и) | Площадь, кв. мк |
|---|---|---|
| 2004 | TSMC | 0,296 |
| январь 2006 | Intel | 0,346 |
| февраль 2006 | Toshiba, Sony, NEC | 0,248 |
| апрель 2006 | AMD | 0,370 |
| апрель 2006 | STM, Freescle, NXP | 0,250¹ |
| июнь 2006 | Texas Instruments | 0,240² |
| ноябрь 2006 | UMC | 0,250³ |
| январь 2007 | TSMC | 0,242 |
| март 2007 | Fujistu | 0,255 |
¹ Оптимизация по энергоэффективности
² С иммерсионной литографией
³ С иммерсионной литографией и низкопроницаемыми межслойными диэлектриками
В этой таблице указана площадь (в квадратных микронах) шеститранзисторной ячейки статической памяти (СОЗУ — из нее, например, состоят почти все виды кэшей процессоров), которой обычно меряют плотность размещения транзисторов для логических микросхем. Это само по себе любопытно, учитывая, что СОЗУ используются в разнообразных регистрах, буферах и кэшах (то есть одно-, а чаще даже двухмерно регулярных схемах), а не в синтезированной логике, почти не имеющей повторений. И тем не менее, именно это мерило долгие годы было главным показателем фактической крутизны возможностей микроэлектронного фаба. Но главное, что все приведенные в таблице техпроцессы — 45-нанометровые (как утверждают эти компании)!
Более того, регулярно выпускавшиеся планы ITRS (International Technology Roadmap for Semiconductors — международный технологический план для [производителей] полупроводников, составлявшийся экспертами из крупнейших фирм и их ассоциаций) содержали рекомендации по основным параметрам техпроцессов для микроэлектронных компаний, то есть для самих себя. А теперь посмотрим, как это все соблюдалось на примере рекомендаций ITRS для логики в 2003 г. в сравнении с фактически найденными фирмой Chipworks (специализирующейся на «инженерной разборке» микросхем) параметрами:

Краткий ответ: никак. К 45-нанометровому процессу Intel достигла длины затвора в 25 нм для традиционных планарных транзисторов (с плоским затвором), на чем и остановилась: дальнейшее уменьшение этого параметра уже ухудшило бы параметры транзистора. Поэтому начиная с техпроцесса 32 нм уменьшались остальные элементы, а вот длина затвора даже немного увеличилась — пока ее не стали считать иначе.

После внедрения транзисторов с «плавниковым затвором» (FinFET) в 22-нанометровом процессе получилось так, что транзисторная плотность все еще могла увеличиваться, пока длина затвора (20–26 нм) и некоторые другие размеры оставались почти неизменными. Из-за свойств многозатворных транзисторов приходится считать так называемую эффективную длину затвора-плавника: две высоты плюс одна ширина. Очевидно, что с такой существенно измененной геометрией бесполезно применять старую схему привязки технормы к «длине затвора».
Дело дошло до того, что на очередном форуме IEDM (International Electron Devices Meeting — международная встреча инженеров электроники) технорму »45 нм» (и все последующие) постановили считать маркетинговым понятием — то есть не более чем цифрой для рекламы. Фактически, сегодня сравнивать техпроцессы по нанометрам стало не более разумно, чем 20 лет назад (после выхода Pentium 4) продолжать сравнивать производительность процессоров (пусть даже и одной программной архитектуры x86) по гигагерцам.
Разница в техпроцессах при одинаковых технормах активно влияет и на цену чипов. Например, AMD использовала разработанный совместно с IBM 65-нанометровый процесс с SOI-пластинами (технология кремния-на-изоляторе нужна для уменьшения паразитных утечек тока, что снижает потребление энергии логики и памяти даже в простое), двойными подзатворными оксидами (во избежание туннелирования электронов из затвора в канал), имплантированным в кремний германием (улучшает подвижность электронов, расширяя межатомное расстояние в полупроводнике), двумя видами напряженных слоев (сжимающим и растягивающим — аналогичная оптимизация, имитирующая меньшую длину канала) и 10 слоями меди для межсоединений. А вот у Intel 65-нанометровый техпроцесс включал относительно дешевую пластину из цельного кремния (bulk silicon), диэлектрик одинарной толщины, имплантированный в кремний германий, один растягивающий слой и 8 слоев меди. По примерным подсчетам, Intel потребует для своего процесса 31 фотолитографическую маску (и соответствующее число производственных шагов на конвейере), а AMD — 42.
В результате из-за значительной разницы в технологиях напряженного кремния и типа подложки (SOI-пластины стоили на тот момент примерно в 3,6 раза дороже простых) конечная цена 300-миллиметровой пластины для AMD была ≈$4300, что на 70% выше цены для Intel — ≈$2500. Кстати, процессоры Intel, как правило, оказываются еще и с меньшими площадями кристаллов, чем аналогичные по числу ядер и размеру кэшей процессоры AMD (по крайней мере, до первого внедрения архитектуры Zen). Теперь ясно, почему Intel стабильно показывала завидную прибыль, а AMD в начале 2010-х едва держалась на ногах, даже избавившись от своих фабрик и перейдя на бесфабричное производство (модель fabless).

По докладам на IEDM можно составить сводную таблицу с параметрами техпроцессов ведущих компаний, актуальных на момент «перелома мышления» — около 2010 г. Из нее видно, что все техпроцессы с «мелкой» технормой (process node) перешли на двойное формирование (DP, double patterning — позволяет изготовить структуры вдвое меньше предельного размера за счет удвоенного числа экспозиций и масок для них) и иммерсионную литографию (использование оптически плотной жидкости вместо воздуха в рабочей зоне литографа), а напряжение питания (Vdd) давно остановилось на 1 вольте (потребление транзистором энергии и без этого продолжает падать, но не так быстро). Куда интересней сравнить длину затвора (LGate), шаг затвора с контактом (Contacted Gate Pitch) и площадь ячейки СОЗУ (SRAM Cell Size).
Тут надо указать, что кэши изготовленных с той же технормой микросхем той же фирмы имеют в случае кэшей L2 и L3 площадь ячейки на 5%–15% больше указанной, а для L1 — на 50%–70% больше. Дело в том, что сообщаемые на IEDM цифры площади тоже являются несколько рекламными. Они верны лишь для одиночного массива ячеек и не учитывают усилители, коммутаторы битовых линий, буферы ввода-вывода, декодеры адреса и размены плотности на скорость (для L1).
Для простоты возьмем только «скоростные» (High Performance) процессы Intel. Для 130 нм длина затвора составляла 46% технормы (при идеале 50%), а через несколько лет — 94%. Тем не менее, шаг затвора уменьшился в те же 4 раза, что и технорма. Однако если разделить площадь ячейки СОЗУ на квадрат технормы, то старым ячейкам нужно ≈120 таких квадратиков, а новым — уже ≈170. У AMD с ее SOI-пластинами — примерно так же. На техпроцессе 65 нм фактический минимальный размер затвора может быть снижен до 25 нм, но шаг между затворами может превышать 130 нм, а минимальный шаг металлической дорожки — 180 нм. Вот тут и видно, что начиная примерно с 2002 г. размеры транзисторов уменьшаются медленней технорм. Выражаясь простым языком, нанометры уже не те…
Особенно интересно в этом плане рассмотреть хорошо уже исследованный техпроцесс Intel »22 нм», представленный в 2012 г. Вооружившись цифрами, можно проверить обещанное компанией. По предварительным цифрам выглядит неплохо: площадь ячейки — 0,092 квадратного микрона для «быстрой» и 0,108 мк² для энергоэффективной версии процесса (это данные 2009 г. для тестовой микросхемы СОЗУ на 22 нм). Для быстрой версии это эквивалентно 190 элементарным квадратам — еще чуть хуже, чем для прошлых технорм. Но Intel продолжает использовать 193-нанометровую иммерсионную литографию и для 14 нм — со все еще двойным формированием. А для 10 нм (которые Intel уже шесть лет пытается довести до ума) — экспозиций и масок уже от трех до пяти (не считая скругления вставок).

При этом для процесса на 10 нм стоимость стадий литографии на единицу площади оказывается примерно в 6 раз больше, чем для 32 нм, а вот площадь меньше в 10 раз (то есть (32/10)² — как при идеальном уменьшении) не стала до сих пор; это, кстати, является причиной того, почему у Intel уже который год вместо обещанных честных 10 нм растет только число плюсов у обозначения технормы »14 нм», которая в очередной раз «улучшается». Тут уже даже неважно, почему Intel и ее коллеги из других компаний решили, что следующие два процесса будут иметь технормы 14 и 10 нм, а не 16 и 11, как можно было ожидать (если каждая следующая — в √2 раз меньше). Ведь цифры теперь мало что значат… Как сказал Паоло Гарджини (Paolo Gargini — ветеран Intel и пожизненный член IEEE): число нанометров промышленной технормы «к этому времени уже не имеет совершенно никакого значения, так как не обозначает размер чего-либо, что можно найти на кристалле и что относится к вашей работе». Скажем, в новейших техпроцессах »7 нм» Samsung и TSMC на кристалле нет ничего, что было бы настолько малым. Например, длина затворов там — 15 нм.

Другая проблема, возникающая в этой связи — стоимость каждого транзистора. Все предыдущие 60 лет развития микроэлектроники основывались на уверенности в том, что даже несмотря на постоянное увеличение цены заводов и разработки техпроцессов и чипов цена самих чипов в пересчете на транзистор будет все время уменьшаться. Так и происходило — примерно до 32 нм, после которых наступил раскол: микросхемы памяти продолжили дешеветь на единицу объема (особенно это коснулось флэш-памяти, которая массово перешла на объемное хранение данных на десятках уровней — технология 3D-NAND), а вот логика сильно затормозилась. Да, последние версии техпроцессов 14 нм предлагают транзисторы все же чуть дешевле, чем у 22 нм —, но именно что «чуть», и это после стольких лет возни. Да и производительность при том же потреблении энергии хоть и растет, но всё медленнее…
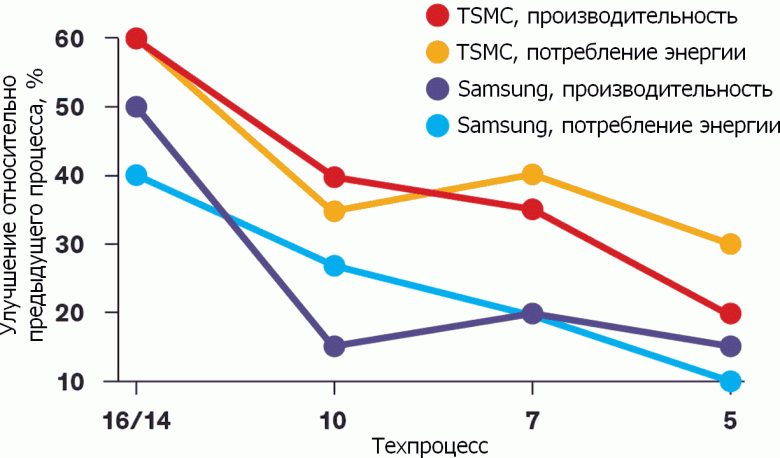
Простейшим решением была бы перепривязка технормы к размеру не затвора, а чего-то другого, более представительного для современного транзистора. Одним числом тут не обойдешься, поэтому предложено использовать две меры длины: CPP, contacted (poly) gate pitch — шаг поликремниевого затвора с контактом (то есть между затворами соседних транзисторов); и MMP, metal-to-metal pitch — шаг первого уровня металлических дорожек, проходящих перпендикулярно поликремниевым линиям, нарезаемым на затворы. Причем теперь нет смысла делить оба шага на два, так как эта половина теперь менее важна. Эта пара значений на некоторое время стала «наименьшим общим знаменателем» в описании логического техпроцесса, а их произведение дает неплохую оценку возможной площади транзистора. Любой фактический транзистор на кристалле будет немного (или много) больше, но никак не меньше этого минимума, и к этому идеалу вполне можно приблизиться при тщательном проектировании и следовании правилам техпроцесса.
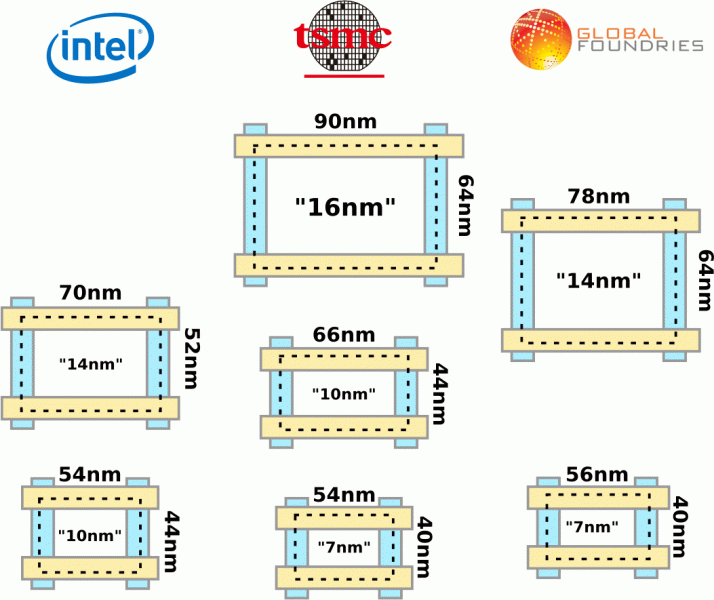
Ситуация второй половины 2010-х годов получилась весьма похожей на то, что переживали в кризис производители продуктов питания: чтобы не увеличивать цены на привычные товары, их просто стали недоливать и недосыпать. Нет-нет, в каждом килобайте кэша все еще ровно 1024 байта, а не 970 (как написано число миллилитров на некоторых «литровых» бутылках молока). Но чиподелы просто окончательно отвязали свои рекламируемые нанометры от физических размеров чего-либо в изготавливаемых микросхемах. TSMC, например, выдала техпроцесс »16FF» с такими же шагами, как у предыдущего на 20 нм. А Intel пошла еще дальше и вспомнила принцип «не можешь отменить — возглавь»: в 2017 г. в ходе ежегодного мероприятия «Производственный день» (Manufacturing Day) старший заслуженный исследователь и директор по архитектурам техпроцессов и интеграции Intel Марк Бор (Mark Bohr) предложил коллегам по отрасли «внести ясность» в определение технологической нормы, изменив его так, чтобы растолковать потребителям, что именно в покупаемых ими микросхемах все-таки улучшается.
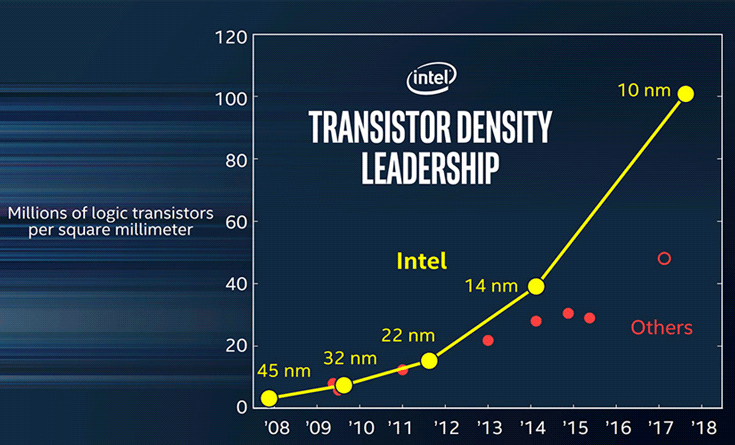
Компания показала график, на котором видно, что переход на каждый следующий шаг приводил к удвоению степени интеграции (удельной плотности компоновки, измеряемой в МТр/мм² — миллионах транзисторов на квадратный миллиметр): на той же площади кристалла помещалось примерно вдвое больше элементов. Однако после техпроцесса 22 нм «другие компании» (по мнению Intel) отказались от этого, продолжив уменьшать число нанометров у технормы, но при минимальном, а то и совсем отсутствующем повышении плотности. По мнению Бора, это связано с ростом сложности дальнейшего уменьшения размеров. (От себя можно добавить: …и цены́ получаемых чипов — с учетом платежеспособности потребителей и получаемого срока окупемости вложений в новый техпроцесс.) В результате декларируемые значения не дают представления о реальных возможностях техпроцесса и его положении на графике, который должен демонстрировать сохранение применимости закона Мура.
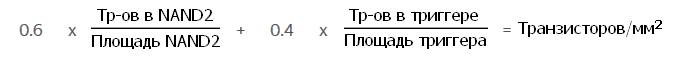
Вместо этого Intel предложила определять возможности техпроцесса по новой формуле, в которую входят площади типовых блоков — простейшего вентиля 2-NAND (двухвходовый логический элемент «и-не») и более сложного синхронного триггера — и число транзисторов в них; их отношения умножены на «правильные» коэффициенты, отражающие относительную распространенность простых (0,6) и сложных (0,4) элементов. Сразу можно заподозрить, что все цифры подобраны для еще более наглядной демонстрации лидерства Intel в сравнении с «другими производителями». Но чуть позже всё стало выглядеть так, будто компания движется вспять, очередной оптимизацией техпроцесса добиваясь худшей плотности: исходный 14-нанометровый процесс (вышедший аж в 2014 г.) имел 44,67 МТр/мм², а дважды обновленный »14++ нм» (образца 2017 г.) — 37,22 МТр/мм². На самом деле это размен с потреблением энергии, которое в «двухплюсовой» версии процесса уполовинилось (опять же — со слов Intel).

Тем не менее, общая идея этого перехода (перепривязка технормы от размера «чего-то там» на кристалле — к оценке среднеожидаемой плотности транзисторов для типичной схемы) имеет не только рекламный смысл, но и практический: если каждый чиподел будет публиковать значение, полученное по новой формуле, для каждого своего техпроцесса, то можно будет сравнивать разные техпроцессы и у одного производителя, и у разных. Причем независимые компании, занимающиеся обратной инженерией (Reverse engineering), типа Chipworks, смогут легко проверять заявленные значения.
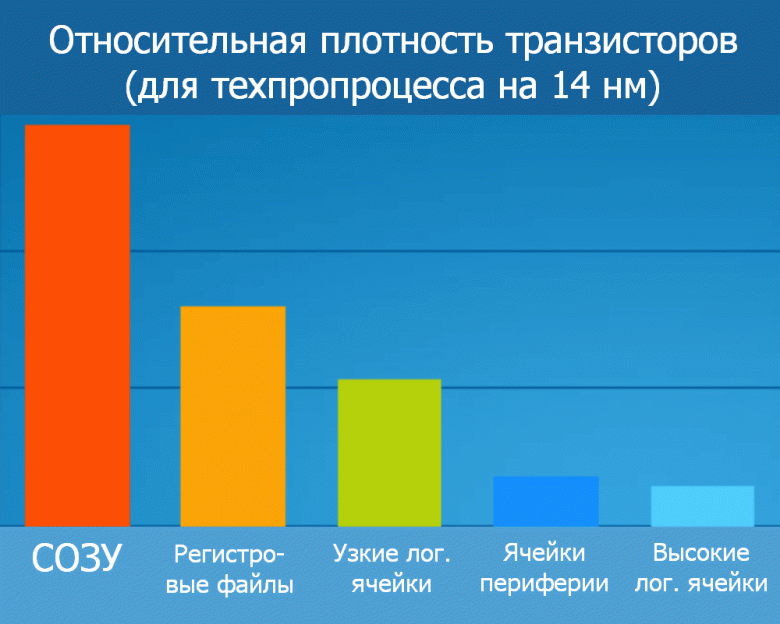
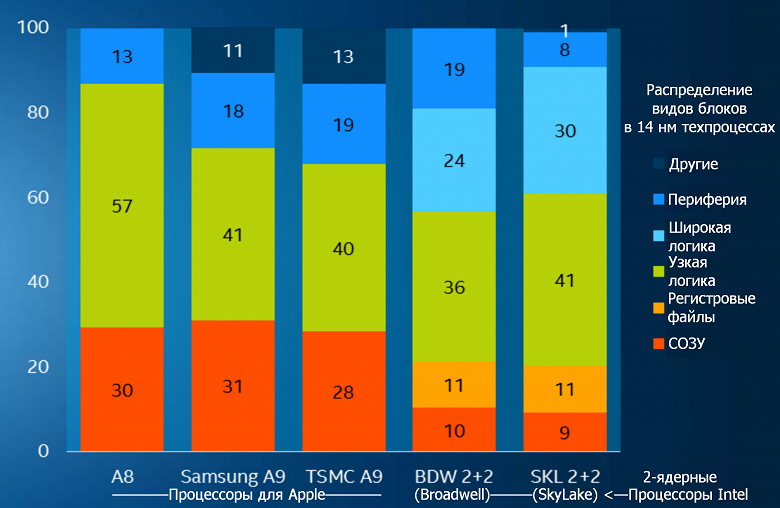
Внимательный читатель тут же заметит, что у микроэлектронной отрасли уже есть один интегральный показатель, позволяющий оценить эффективность техпроцесса по плотности транзисторов без привязки к величине нанометров: вышеупомянутая площадь шеститранзисторной ячейки СОЗУ, также являющейся распространенным строительным блоком для микросхем. Число ячеек заметно влияет на общую степень интеграции в виде среднего числа транзисторов на единицу площади кристалла. Тут Intel пошла на компромисс, предложив не отказаться от площади СОЗУ, а сообщать ее отдельно — учитывая, что в разных микросхемах соотношение сумм площадей ячеек памяти и логических блоков сильно отличается. Впрочем, даже с этим учетом на практике пиковая плотность невозможна и по другой причине: плотности тепловыделения. Чипы просто перегреют себя наиболее горячими местами, расположенными слишком близко друг к другу при высокоплотном дизайне. Поэтому их разряжают чем-то менее горячим (например, емкой памятью) и/или малоплотным (как контроллеры периферийных шин). И это еще без учета аналоговых элементов, которые в такие формулы не вписываются в принципе…
Уменьшение транзисторов типа FinFET позволило весьма эффективно уменьшать управляющий ток (подаваемый на затвор для переключения) ростом высоты плавников и уменьшением их шага. С какого-то момента много затворов для высоких частот уже оказываются не столь нужны, и их число тоже можно уменьшить — вместе с числом подходящих к ним дорожек, причем без просадки скорости. В результате недавно введенная метрика «CPP × MMP» «развалилась», поскольку не учитывает меньшую высоту логических ячеек. Еще более скоротечной компромиссной полумерой было домножение ее на минимальное число дорожек металла для построения логического вентиля: «CPP × MMP × Tracks», сокращенно GMT. Однако не все дальнейшие оптимизации могут быть отображены даже в новой версии формулы. Например, расположение контакта непосредственно над затвором (а не сбоку от него) снижает высоту ячейки, а использование одного бокового ложного затвора вместо двух для смежных вентилей уменьшает ее ширину. Ни то, ни другое в формуле не учитывается, что и было формальной причиной для перехода на подсчет мегатранзисторов логики на квадратный миллиметр.

Самая свежая из нынешних технологий литографии — ЭУФ (экстремальный ультрафиолет). Она использует длину волны 13,5 нм, ниже которой пока коммерчески пригодной дороги нет. А это значит, что размеры чего-либо на кристалле скоро совсем перестанут уменьшаться. Чиподелам, производящим логику (особенно процессоры и контроллеры), придется подсмотреть у своих «пекущих» память коллег технологии монолитной объемной компоновки, располагающие транзисторы (а не только связывающие их дорожки) слоями. В результате удельная плотность транзисторов на единицу площади будет расти уже с числом их слоев. Потому новой идеей было переопределение буквы T в формуле с «Tracks» на «Tiers», на которую надо не умножать, а делить. Кстати, предложил это тот же Паоло Гарджини, ныне ставший главой IRDS (IEEE International Roadmap for Devices and Systems) — организации «международного плана для приборов и систем» и преемницы почившей в бозе ITRS, собрания которой стали бессмысленными вследствие кризиса общего целеполагания мировой полупроводниковой отрасли и ввиду предсказания остановки уменьшения размеров транзисторов уже в 2028 г.
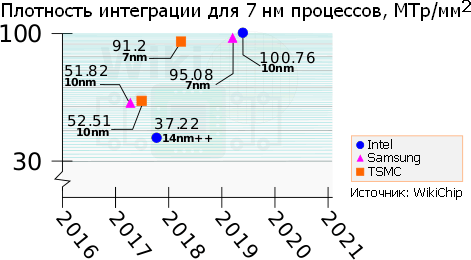
С момента предложения формулы Бора прошло три года, и без труда можно заметить (на примере Intel и AMD — двух крупнейших производителей процессоров, сообщающих о своих новинках хоть сколько-нибудь подробно), что компании не перестали расхваливать свои чипы с упоминанием пресловутых нанометров. Зато Intel и AMD за это время поменялись местами: Intel, кажется, уже отчаялась доделать свой техпроцесс 10 нм и раздумывает над переходом сразу на что-то еще меньшее (неважно, с какой цифрой); зато AMD рекламирует свои новые процессоры архитектуры Zen2 как носящие 7-нанометровые транзисторы, подчеркивая преимущество над конкурентом. Впрочем, мелкими буквами указано, что речь идет только о кристаллах CCD (Core Complex Die), где размещены 8×86-ядер и мегабайты кэша, а изготовлены они на фабе TSMC и имеют площадь всего 74 мм². А вот контроллеры памяти и периферии расположены на отдельном чипе — 12-нанометровом «client I/O Die» (cIOD) или 14-нанометровом «server I/O Die» (sIOD); оба вида делаются на заводе GlobalFoundries и имеют бо́льшую площадь из-за более грубого техпроцесса, однако по той же причине они и дешевле.

Свежайший пример нелинейного улучшения плотности — параметры процессоров (точнее — SoC, однокристальных систем) для игровых приставок Microsoft серии XBox. Все эти чипы проектировались силами AMD, а производятся у TSMC, поэтому сравнивать их параметры весьма удобно. При почти неизменной площади 360–375 мм² переход от 28 нм к 16 увеличил плотность не втрое (как можно было ожидать при линейном уменьшении размеров транзисторов), а всего на треть (сравнивая XBox One и XBox One X). А следующий переход к 7 нм должен был дать аж 5-кратное уплотнение, но выдал только 2,3 раза. Цена процессора при этом не забывала расти.
Год назад, видя такие дела, в университете Беркли (Калифорния, США) собрались видные теоретики микроэлектроники (в том числе все три изобретателя «финфетов»: Chenming Hu, Tsu-Jae King Liu и Jeffrey Bokor) и… Да-да, нетрудно догадаться: они предложили новую, очереднадцатую метрику. Назад к нанометрам возвращаться никто не призывает. Наоборот, профессоры и инженеры решили вместо одной цифры использовать три, к плотности транзисторов логики (DL) добавив плотность транзисторов памяти (DM — в битах/мм²; и это не старая-добрая СОЗУ, а еще более плотная динамическая память — ДОЗУ, или DRAM) и плотность связующих кристалл с подложкой шариковых выводов (DC — в тысячах на мм²). Последний параметр знаменует наибольшее отклонение от стандартных мерил техпроцессов, так как не имеет никакого отношения к транзисторам. Тем не менее, в последние годы стало ясно, что подвод питания и обеспечение всё большей пропускной способности и меньших задержек при доступе к памяти требуют от чиподелов показывать заметный прогресс и в этой величине.
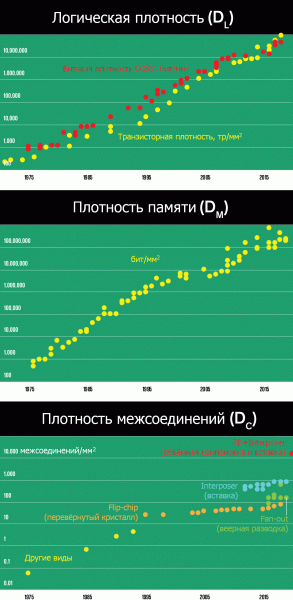
Как и версия Intel, новая метрика LMC (названая по индексам плотностей) использует интуитивное правило «больше — лучше» для всех трех своих цифр и не имеет верхних границ, обусловленных какими-то физическими пределами. Это дает определенную психологическую уверенность, что прогресс всё еще неостановим — что весьма важно в свете наблюдаемого в западных вузах падения популярности кафедр микроэлектроники, физики полупроводников, материаловедения и смежных прикладных наук. При этом числа остаются вполне уместными и отражающими возможности описываемых ими техпроцессов с точки зрения конечного пользователя: компьютеры продолжают улучшаться по основным параметрам логики, памяти и периферии — производительности, энергоэффективности и цене. Причем рост всех трех плотностей пока не прерывается и происходит одновременно, образуя важный баланс в развитии вычислительной техники — от смартфонов до суперкомпьютеров. Проще говоря, по этой метрике закон Мура все еще работает.
Ложкой дегтя будет тот факт, что список производителей новейших «бочек меда» сократился до удивительного минимума. А именно: 180 нм умеют «печь» 29 фирм в мире, 130 нм — 26, 90 нм — 19, 65–40 нм — 14, 32–28 — 10… Дальше происходит как в известной песенке-считалке «Десять негритят»: Panasonic, STM, HLMC, UMC, IBM, SMIC, GF, Samsung, TSMC и Intel отправились печь чипы на 22–20 нм; первые трое обожглись, и их осталось семеро. На 16–14 нм сдалась IBM (продавшая свой самый крутой фаб коллегам из GlobalFoundries). А 10 и 7 нм и вовсе осилила лишь последняя тройка — пока не подтянется «Альянс общей платформы» (Common Platform Alliance: объединение GF, IBM, STM, UMC и Samsung — в котором владельцем обновленных фабов, видимо, останется только последняя); причем 7 нм у Intel появятся «в 2021 г.» (читай — в неопределенном будущем). То есть сложность и стоимость изготовления «тонких» техпроцессов и фабов для них оказывается столь запредельной, что это уже вопрос банального выживания на рынке. Куда уж тут до конкуренции и честности подачи нанометров…
Полный текст статьи читайте на iXBT


